
 NETWORKING
›
NETWORKING
›
 CLOUD PLATFORM
›
CLOUD PLATFORM
›
 CYBER SECURITY
›
CYBER SECURITY
›
 ENDPOINT SECURITY
›
ENDPOINT SECURITY
›
 DATA SECURITY
›
DATA SECURITY
›
 SPECIFICATION
›
SPECIFICATION
›
 IDENTITY & ACCESS MANAGEMENT
›
IDENTITY & ACCESS MANAGEMENT
›
 SERVER AND DEVICE
›
SERVER AND DEVICE
›
 SERVE & SERVICE
›
SERVE & SERVICE
›
 DESIGN & OFFERING NETWORK SYSTEM
›
DESIGN & OFFERING NETWORK SYSTEM
›
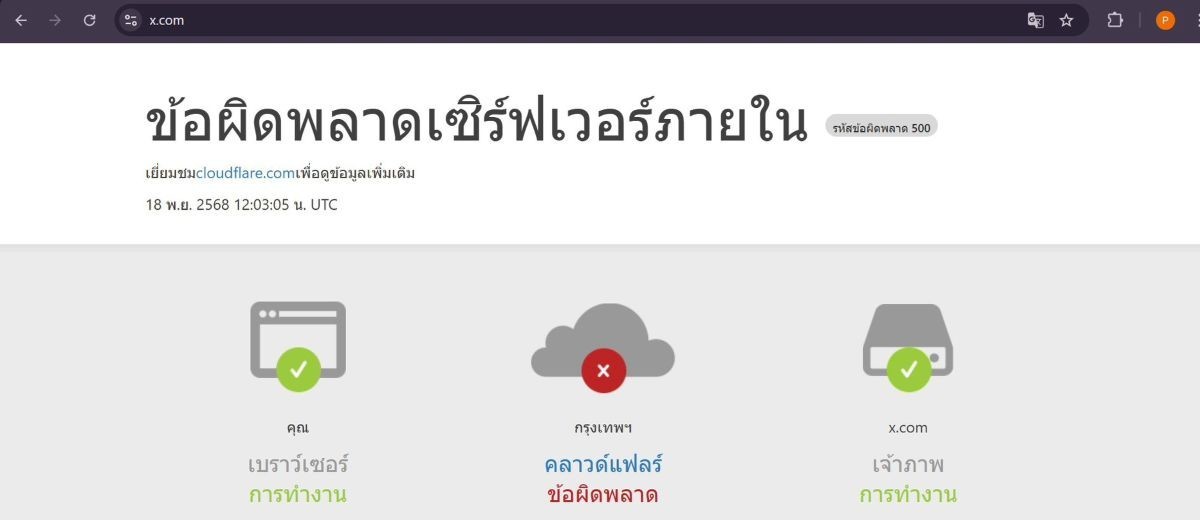
📰 Cloudflare ล่มครั้งใหญ่! เปิดฉากวิกฤตอินเทอร์เน็ตทั่วโลก ต้นตอ "ไฟล์กำหนดค่า" ใหญ่เกินคาด
ซานฟรานซิสโก, 19 พฤศจิกายน 2568 - เครือข่ายอินเทอร์เน็ตทั่วโลกเผชิญหน้ากับความโกลาหลครั้งใหญ่เมื่อคืนที่ผ่านมา หลังผู้ให้บริการโครงสร้างพื้นฐานด้านความปลอดภัยและเครือข่ายชั้นนำอย่าง Cloudflare ประสบปัญหาการล่มของระบบ ซึ่งส่งผลกระทบต่อเว็บไซต์และบริการดิจิทัลหลายร้อยแห่ง ตั้งแต่แพลตฟอร์มโซเชียลมีเดียไปจนถึงบริการ AI ที่สำคัญ
💔 ผลกระทบ: ธุรกิจทั่วโลกหยุดชะงัก
เหตุการณ์เริ่มต้นขึ้นประมาณ 18:20 น. ตามเวลาประเทศไทย (11:20 UTC) โดยผู้ใช้งานและบริษัทต่าง ๆ รายงานว่าไม่สามารถเข้าถึงบริการออนไลน์จำนวนมากได้ แพลตฟอร์มที่ได้รับผลกระทบอย่างหนัก ได้แก่:
• X (Twitter เดิม)
• ChatGPT และบริการ AI อื่น ๆ
• Spotify
• Discord
• Canva
• เว็บไซต์ข่าวสารและอีคอมเมิร์ซจำนวนมากที่ใช้บริการ CDN และ WAF ของ Cloudflare
ผู้ใช้ส่วนใหญ่ได้รับข้อความแจ้งข้อผิดพลาดที่เกี่ยวข้องกับ Cloudflare หรือข้อผิดพลาดประเภท "500 Internal Server Error" โดยเหตุการณ์นี้ตอกย้ำว่า Cloudflare คือ Single Point of Failure (SPOF) ที่สำคัญของโลกดิจิทัล
🔍 ต้นตอ: Latent Bug และไฟล์ยักษ์
Cloudflare ออกมายืนยันอย่างรวดเร็วว่า ไม่ใช่การโจมตีทางไซเบอร์ แต่เป็นปัญหาทางเทคนิคภายในที่เกิดจากบั๊กที่ซ่อนอยู่ (Latent Bug) ที่ถูกกระตุ้นโดยการเปลี่ยนแปลงการกำหนดค่าตามปกติ
• ระบบที่เกี่ยวข้อง: ปัญหาเกิดขึ้นในระบบ Bot Management ซึ่งเป็นส่วนที่จัดการทราฟฟิกภัยคุกคาม
• สาเหตุเฉพาะ: Cloudflare ระบุว่า ไฟล์กำหนดค่า (Configuration File) ที่ระบบสร้างขึ้นโดยอัตโนมัติเพื่อจัดการทราฟฟิกนั้น "มีขนาดใหญ่เกินกว่าที่คาดการณ์ไว้" ($grew$ $beyond$ $an$ $expected$ $size$)
• ผลกระทบเป็นลูกโซ่: ขนาดไฟล์ที่ใหญ่ผิดปกตินี้ได้กระตุ้นให้ซอฟต์แวร์หลักที่รับผิดชอบการจัดการทราฟฟิกเกิดการล่ม (Crash) และส่งผลกระทบเป็นลูกโซ่ไปยังบริการสำคัญอื่น ๆ ของ Cloudflare เช่น Workers KV (บริการจัดเก็บข้อมูลหลัก), Web Application Firewall (WAF) และระบบ DNS Resolution
🛠️ การแก้ไขและการรับผิดชอบของ Cloudflare
Cloudflare ใช้เวลาประมาณ 3 ชั่วโมงในการระงับเหตุการณ์ โดยวิธีการแก้ไขที่รวดเร็วคือการ ย้อนกลับไฟล์กำหนดค่า (Rollback) ของ Bot Management ไปสู่เวอร์ชันที่ทำงานได้ตามปกติ และสั่งหยุดการสร้างไฟล์กำหนดค่าที่ผิดพลาด
• คำขอโทษ: Cloudflare ได้กล่าวขอโทษอย่างเป็นทางการต่อลูกค้าและชุมชนอินเทอร์เน็ต โดยยอมรับว่าเหตุการณ์นี้เป็นสิ่งที่ "ยอมรับไม่ได้"
• คำมั่นสัญญา: บริษัทให้คำมั่นว่าจะดำเนินการตรวจสอบอย่างละเอียด (Post-Mortem) และปรับปรุงระบบการจัดการการกำหนดค่า (Configuration Management) และการแยกส่วนบริการ (Service Isolation) ให้ดีขึ้น เพื่อป้องกันไม่ให้ความล้มเหลวของบริการเดียวลุกลามไปยังระบบสำคัญอื่น ๆ
🌊 แรงกระเพื่อม: เสียงเรียกร้อง Multi-CDN
เหตุการณ์นี้สร้างแรงกระเพื่อมอย่างรุนแรงในชุมชนเทคโนโลยี โดยเฉพาะในกลุ่มนักพัฒนาและสถาปนิกโครงสร้างพื้นฐาน
• การพิจารณา Multi-CDN: บริษัทเทคโนโลยีขนาดใหญ่ที่ได้รับผลกระทบ รวมถึงผู้ประกอบการรายย่อย ต่างพิจารณาหรือเร่งดำเนินการย้ายไปใช้กลยุทธ์ Multi-CDN (การใช้ผู้ให้บริการ CDN หลายรายพร้อมกัน เช่น Cloudflare คู่กับ Akamai หรือ Fastly) เพื่อกระจายความเสี่ยง
• การแยกส่วน DNS: มีการเรียกร้องให้ใช้ผู้ให้บริการ DNS สองรายที่แยกจากกันโดยสิ้นเชิง (Multi-Primary DNS) เพื่อให้การเปลี่ยนเส้นทางทราฟฟิก (Failover) ยังคงทำงานได้แม้ว่า Cloudflare จะมีปัญหาทั้งระบบ
• ทบทวน SLAs: ธุรกิจต่าง ๆ เตรียมทบทวนสัญญา Service Level Agreements (SLAs) กับ Cloudflare และพิจารณาความคุ้มค่าของการใช้ผู้ให้บริการเดียวเทียบกับค่าใช้จ่ายที่เกิดจากการหยุดชะงักของบริการ (Cost of Outage)
เหตุการณ์ครั้งนี้ถือเป็นการเตือนที่สำคัญอีกครั้งถึงความเปราะบางของโครงสร้างพื้นฐานอินเทอร์เน็ตที่พึ่งพาผู้ให้บริการขนาดใหญ่ไม่กี่ราย และกระตุ้นให้เกิดการลงทุนในความยืดหยุ่นทางไซเบอร์ (Cyber Resilience) มากขึ้นในอนาคต
To give you a better experience, by continuing to use our website, you are agreeing to the use of cookies and personal data as set out in our Privacy Policy | Terms and Conditions

